The rise of the 'new' issues: Data Motion
By joe
- 8 minutes read - 1525 wordsI’ve been talking about data motion (moving data between place “a” and “b”) as a problem for a long time now.
You can summarize it easily in a very simple equation, and use that to explain what is going wrong, and estimate how much we are going to suffer going forward. In a nutshell, data motion is measurable in the time it takes to copy a chunk of data between ‘places’. What defines a ‘place’ is flexible, and you can use this for modeling many things as it turns out.
Ok, without further ado … here it is …
T(data motion) = L(access) + S(data)/B*(interface)
Where
* T(data motion) is the time in seconds to achive the intended data motion
* L(access) is the latency of access in seconds ... how long you have to wait for the thing you want to be accessible ... in the case of memory, this can be tens to hundreds of nanoseconds (10^-9 s), in the case of disks it could be in milliseconds (10^-3 s).
* S(data) is the size of the data to move, usually in bytes, but other measures are fine. Networking folks use bits.
* B*(interface) is the effective bandwidth of the interface. Ill make an argument about this in a moment.
The B*(interface) is the effective bandwidth for the interface. Think of it as the fraction of the bandwidth of the interface you can make use of. You can’t always make fully effective use of an interface due to contention, or inefficiency, or … well … many possibilities that interfere with full interface access. I like to try to model B*(interface) as
B*(interface) = B(interface) * (1 - contention_fraction)*E(interface)
Where
* B(interface) is the native uncontended interface bandwidth, which is **the minimum** of all bandwidths in the serial data path
* contention_fraction is the fraction of the interface available to the process ... if you have 10 requesters for an interface, on average, you will get 1/10th the interface per process. I call that the 1/N rule of contention. This is very important in HPC with a large number of processes contend for limited resources. More on that in a moment.
* E(interface) is the native efficiency of the interface. So if you are using a data protection scheme ... say using 10 bits of data and 8 bits to protect the data, you have a native efficiency of 10/(10+8). Its basically a measure of how much of the bandwidth of the interface, if uncontended for, is available to data as compared to metadata, etc.
You can directly measure B*(interface). Every time we do a dd to disk from /dev/zero, we are measuring the effective bandwidth of one (or two, or …) disk controllers. Every time we do this over an iSCSI or NFS or similar link we are measuring the effective bandwidth of that link. We can measure the efficiency of the link by sending raw data over it of various sizes, and examining the shape of the curve.
Ok, now that I have laid the groundwork, allow me to state the problem.
S(data) is growing exponentially fast, while B* is remaining constant for long periods of time. The impact of this is stunning, as are the implications.
First, what I mean is that
S(data) := S(t=t0) * F(t)
Where S(t=t0) is a data size “scale”, basically the S(data) at some time = “t0” which can be arbitrarily chosen point, and F(t) is a monotonically increasing function of time.
Exponential data growth means S(data) = S(t=0) * exp( alpha * (t-t0) ) for positive values of alpha, and t > t0.
Some folks might say that this is a Chicken Little argument, that the sky isn’t really falling, and Dedup and other technologies are going to save us.
Sadly, such people would be wrong. Medical imaging is on an exponential growth curve. As are many other fields. One example is genomics.
[
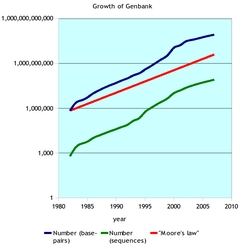
](/images/genbank-07.png)
Basically this arises from the fact that measurement and data collection technology is evolving. Images are gaining resolution with better cameras. Which means that the cost per additional bit of accuracy/measurement is dropping. So provide more bits. In genomics, sequencers are coming online to decrease the cost of providing reads. Universities and research institutes are gearing up for massive projects to sequence not just one or two organisms over a decade span, but multiple species per small (and decreasing) unit of time. The tools that process this information are getting faster and better over time. Computational intensity is growing over time. That is, it is getting harder to operate on the data, because to operate on the data, you have to … read the data … . Ok, you might say why not look at the LHC model. Distribute pre-digested data to tiers which then digest and repeat. This is a good model. And not everyone can afford this model. It requires very high B*(interface) at various locations, and a single centralized data source. It is expensive in terms of the infrastructure required to move the data. But this centralized model isn’t necessarily a correct solution mapping for all problems. It works well for them, but it might not work well for a genome center. Or a medical image processing system. The underlying data network has to be reasonable for the problem, and correctly implemented. There is a cost to B (and B*). These costs are non-zero, and really, quite high. So if you can’t amortize theses costs over a huge distributed processing system (ala LHC), the economics of this type of solution may be troubling. I didn’t talk much about contention yet, I should. 8 processes contending for a single resource simultaneously will yield a (typically) 1/8th share among the contenders for that resource. If there is a duty cycle associated with this usage, basically a probability that it will be busy during some interval, the actual contention level will be lower. AT&T; had do do this sort of analysis when estimating how many shared telephone wires to build in a particular city (many moons ago). Too many, and some go unused on average (which wastes the investment). Too few, and you get contention, and often blocking under normal use cases. We see this today with Cell providers who don’t have sufficient back-haul bandwidth occasionally getting unable to initiate call due to “all circuits busy”. Thats a nice way to say they have achieved maximal saturation of their interface, and lack bandwidth for more. Now think about this contention in terms of memory buses in computers. Or network interfaces. The folks in the IT world are falling all overthemselves with virtualization. It reduces the cost to stand up the N+1th resource. It allows them a much denser packing of servers, which may often be partially idle. And many folks want to push this into HPC. Now look at that contention issue again. One memory bus, say 4 codes sharing it at once. They aren’t co-operating on the resource, they are competing for it. This reduces the B* of this resource for them. Virtualization increases contention. If you are performance limited in one of the aspects of your computation, virtualization is likely to exasperate this. So as you have 8 processes all vying for use of the network, and its single port bandwidth … think about the aspect of what this will do to the performance per unit. Data motion will be impeded. And if your processes depend upon data motion (most do), its going to take you longer to achieve solution. When you look at cloud computing, the time to return meaningful results is an important measure, and the cost of obtaining those results as compared to alternative scenarios is also critical to management in order to figure out how to apportion limited resources. The time to move the data to the cloud (the L(access) for the transfer) can be huge. Moving 1GB of data a 1MB/s would take 1/3 of an hour. Most end user sites here in the US, outside of academia, don’t have 1 MB/s upload rates. More typically they are 0.2 MB/s or less (1.5 Mb/s). The Gigabyte takes 5000s+ to move. More than an hour. Especially since this link is contended for, with VOIP, data traffic, etc. Add more than one user moving their model, and you see the problem. Data motion is hard. It is not cheap. It is slow. And data motion is likely to be the impediment for cloud HPC computing for a while. Virtualization is the other issue, and it will impact some users. But data motion is the difficult one. I know, some people talk about moving the data and parking it. Which works well if all your colocated computing resources are close, in a data motion sense, to the data. What if you have different functionality at different locations in the cloud? Data has to follow it. Until we get 10 GbE to the building from ISPs, as cheap as possible, data motion is going to be a problem. 1GbE would be nice, but with current data growth rates, unfortunately it will be little more than a band-aid.